Restructor
Restructor is a system / algorithm to automatically refactor entire code-bases down to their least-redundant form (normal form). It’s a research project I worked on 2005-2010. I’ve made two prototype implementations of it so far.
Why?
The motivation comes from the thinking that the majority of problems in code quality come from code being under-abstracted (copy paste code) or over-abstracted (over-engineered). Avoiding either pitfal is hard work: it requires constant refactoring, which gets exceedingly hard the more a code-base grows. If you don’t refactor however, you make future refactorings even harder (refactoring is easiest when code is “fresh”), and future changes harder and more error prone.
The simplest (and very effective form) of refactoring is “code compression”: replace code by a function call when you find two instances, and inline a function when the number of callers drops to 1. This is an exceedingly tiresome algorithm for humans, but should be easy for computers!
Note that plenty of IDEs offer “refactoring” operations, but this is quite unlike that. Restructor is intended to work on an entire code-base at once, cleaning up ALL code automatically, until it can find nothing to improve anymore. Imagine taking a program, and doing a lot of copy-pasting, moving and deleting of code, then pressing a button, and all your code obeys a “Once and Only Once” design.
The prototype
The most complete is a prototype in C# and WPF (random test code example):

It features:
- A visual programming environment.
- Tries to make code look as much as possible like a textual language for familiarity, but is a tree based editor underneath.
- Any node or insertions can be converted back and forth to textual code for familiar editing.
- On the fly feedback of parse/type errors (node shown in red, error when hovered over).
- Simple integrated debugging.
- A parser, type checker and code generator for the built-in Restructor language.
- The type checker handles generics.
- The code generator outputs directly to CLR bytecode, so is both convenient and fast. Saves out stand-alone executables.
Examples
First, a simple example. From this starting code
((1 - 3) + (1 - 4)) * ((2 - 7) + (2 - 6))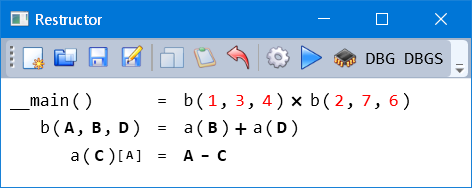
As you can see it has created functions representing the repeating + (b) and - (a) expressions. It has also recognized that the left-hand-side of a is always the same for each side of b, so it is an argument to the b function, and a free variable to the a (indicated in []), which is a local function to b (shown by the indentation).
Here’s an example showing it can correctly deal with side-effects:
x = 2 => ((x = 3) + x) * ((x = 5) + 4)This introduces a variable x, then assigns to it in two similar ways. It wants to make the pattern (A = B) + C into a function, which would make x into an argument, but the first occurrence is blocking it from doing so, because x would have value 2 as argument, whereas it should have value 3 by the time it is evaluated (the language has a strict eager left to right evaluation ordering). It gets around that by recognizing the order dependency and forcing x into a function, so it is always evaluated when needed:

The ! is a shortcut to force the evaluation of a function. Typically these functions would be shown inline to be easier to follow, but that hasn’t been implemented yet.
Now that is really trivial, but it works on any size code. This code is what you get if you randomly copy paste code a bunch of time, and is super hard for a human to discover any structure in it:
2+4*3-6+1*9-2+4*3-6+1*9-5+7*6*8-2+4*3-6+1*9-5+2+4*3-6+1*9-5+7*6*8-7*6*8-7+7*2+4*
3-2+4*3-6+2+4*3-6+1*9-5+2+4*3-6+1*9-2+4*3-6+1*9-2+4*3-6+1*9-5+7*6*8-2+4*3-6+1*9-
5+2+4*3-6+1*9-5+7*6*8-7*6*8-7+7*2+4*3-2+4*3-6+2+4*2+4*3-6+1*9-2+4*3-6+1*9-5+7*6*
8-2+4*3-6+1*9-5+2+4*3-6+1*9-5+7*6*8-7*6*8-7+7*2+4*3-2+4*3-6+2+4*3-6+1*9-5+2+4*3-
6+1*9-5+7*6*8-7*2+4*3-6+1*9-5+7*6*8-7*8-2+4*3-6+1*9-2+4*3-6+1*9-5+7*6*8-2+4*3-6+
1*9-5+2+4*3-6+1*9-5+7*6*8-7*6*8-7+7*2+4*3-2+4*3-6+2+4*3-6+1*9-5+2+4*3-6+1*9-5+7*
6*8-7*2+4*3-6+1*9-5+7*2+4*3-6+1*9-2+4*3-6+1*9-5+7*6*8-2+4*3-6+1*9-5+2+4*3-6+1*9-
5+7*6*8-7*6*8-7+7*2+4*3-2+4*3-6+2+4*3-6+1*9-5+2+4*3-2+4*3-6+1*9-2+4*3-6+1*9-5+7*
6*8-2+4*3-6+1*9-5+2+4*3-6+1*9-5+7*6*8-7*6*8-7+7*2+4*3-2+4*3-6+2+4*3-6+1*9-5+2+4*
3-6+1*9-5+7*6*8-7*2+4*3-6+1*9-5+7*6*8-7*8-7*9-5+2+4*3-6+1*9-5+7*6*8-7*6*8-7+1*9-
5+7*6*8-7*8-7+1*9-5+7*6*8-7*2+4*3-6+1*9-5+7*6*8-7*8-7*9-5+2+4*3-6+1*9-5+7*6*8-7*
6*8-7+1*9-5+7*6*8-7*8-7*8-7*8-7*9-5+2+4*3-6+1*9-5+7*6*8-7*6*8-7+1*9-5+7*6*8-7*8-
7*9-5+2+4*3-6+1*9-5+7*6*8-7*6*8-7+1*9-5+7*6*8-7*8-7-6+1*9-5+2+4*3-6+1*9-5+7*6*8-
7*2+4*3-6+1*9-5+7*6*8-7*8-7*9-5+2+4*3-6+1*9-5+7*6*8-7*6*8-7+1*9-5+7*6*8-7*8-7+7*
6*8-7*2+4*3-6+1*9-5+7*6*8-7*8-7*9-5+2+4*3-6+1*9-5+7*6*8-7*6*8-7+1*9-5+7*6*8-7*8-7Which Restructor then turns into this crazy code:

Now that is not necessarily readable either, but it is fully non-redundant. All code structures appear exactly once, and the functions are chosen such that the most frequent code structures get the simplest abstractions.
Why not?
This in theory sounds great, so why is Restructor not necessarily the answer to the “Software Crisis” ?
Automatic re-organization destroys the value of the programmer mental model
The easiest way to explain this is with an analogy: picture the stereotypical professor office, full of stacks of books an papers. Now imagine you’d sneak into his office, reorganize all his stacks, and when he returns, say “look, I’ve sorted all your books by color!” Would he be happy for your help, or want to kill you? Likely the latter.
A similar thing can happen to programmers, their understanding of code can get very tied to the organization of the source code, naming, and many other details. The restructor algorithm being “global” means that it can potentially move a LOT of code around. In particular, it may constantly shift boundaries of functions as it moves code in and out of them, depending on the set of callers.
There are ways around this, but they are challenging:
- For starters, you’d probably want to tie naming of things not to functions, but to expressions. This way, as code moves around, these names are not lost.
- You’d want some way to sort code such the refactored version ends up close to where the code originally was.
- Programmers would probably be best of using a Restructor-based language for new projects only, not for large existing code bases. The effect on existing code would be too dis-orienting.
- Similarly, you’d want to invoke Restructor as often as possible, after every unique edit. That way an editor could high-light what just happened (similar to a diff), allowing you to follow along with the new code structure, and name newly formed functions if necessary, minimizing the jarring effect.
- You could try making the algorithm not global, by basically only allowing it to do 1 refactor at a time. The current algorithm is not able to do this, because it essentially does many tiny refactoring steps to arrive at the end result, but no doubt it can be done. It would have the advantage that it would be easier for the programmer to follow along, and it could incrementally improve even an existing code-base that has never been refactored.
- You could make it work specifically with graphical languages, like e.g. dataflow graphs, that have less naming and less expectations on code organization to start with.
Not easily suitable for multi-person projects
The dis-orienting nature of code moving around would get pretty crazy with multiple people working on the same code-base. Merging code would be very hard since so much can change. A shared editing environment would pose its own challenges in terms of dealing with others simultaneous edits and refactorings.
The only practical way to work with multiple people is to make each person work on an isolated sub-system at once, which communicate over interfaces that are not subject to refactoring. But this would obviously miss out on many cross-module refactorings and allow code quality of the overal code-base to deteriorate.
It wouldn’t be easy for people to retain knowledge of a code-base they haven’t worked on for a long time, since the code may have changed entirely.
It’s not a great match for most existing languages
As you saw, the prototypes use a new language and editing environment. Like the section above shows, it is challenging to make this kind of system work well for the programmer, so being able to design everything from the ground up to work with it is likely going to give a better experience.
It can be done with existing languages, but the resulting code may be a bit foreign. For example, to freely move code around, Restructor must be able to move code that has side effects and/or whose execution frequency is 0..N, not 1. For example:
for (int i = 0; i < max; i++) print(i);
for (int i = 0; i < max; i++) sum += i;Clearly here the algorithm should put the loop in a function, and make the body an argument. But to do that, the argument needs to become a function value (lambda). Syntax for lambdas (both the type and the value) in many languages are verbose and clumsy looking. Restructor would possibly introduce a lot of them, and many programmers would find them hard to follow. Yet if you restrict refactoring to code that does not require a lambda, you miss out on a lot of refactorings arbitrarily.
A new language can try to make these as clear as possible without being verbose, and try to introduce language features to reduce their need as much as possible (e.g. by using more functional features where possible).
The algorithm in detail
Data structures:
- AST nodes have a type and list of children
- The node type is actually an object from a hierarchy that stores any information beyond the children, e.g. literals, or list of arguments for a function.
- A program is a list of functions, each with a root node.
- (transient) A TwoNode is a tuple of two nodes, always a parent and one of its children.
The algoritm:
While there is stuff to refactor, repeat (one pass):
- Iterate thru all code, and add every possible TwoNode you find into a map from each possible kind of TwoNode to a list of occurrences. (collecting structurally equivalent copies in the code). For example, if the code is
(1 + 2) * (1 + 3), then parent+with child1(at index 0) will be the highest occurring TwoNode.- Any node may only participate in one TwoNode, since a refactor is destructive. Combinations that didn’t get to participate can be picked up by next passes.
- Add all map items where the list has at least 2 items to an overal list, and sort that by occurrences. If this list is empty, we’re done refactoring!
- Go through the overal list in order of number of occurrences:
- Create a new function that will have the TwoNode as body. Generate placeholders for all children of the parent that are not the given child, and all children of the child. So here the function would be:
f(x) = 1 + x- if the child was already a placeholder, it becomes a free variable of the new function, similarly if either node is a function, then its free vars are added to the new function.
- Find the lowest common ancestor function that dominates all occurrences, so function is defined as local as possible. Make that the parent function. (this could be skipped if all functions were global).
- if the child wasn’t the last child: (because if it is the last child, the order of evaluation vs the other
children doesn’t change, so no special action is needed!)
- Find all side-effects in all children of the child. This takes the entire call graph into account from this node.
- If there are any side - effecs, for each following child, for each of its occurrences, check if the two children are order dependent. E.g.
g(a = 1, a)org(a, a = 1)are order dependent, and we have to ensure to retain the evaluation order.g(a = 1, b)is not order dependent. - If the other child is order dependent, we can’t make it into a regular argument, but instead we make it into a function value argument, so it is normal-order evaluated and doesn’t change the order of evaluation.
- Now replace all occurrences with our new function, so our expression becomes
f(2) * f(3). - If any arguments are equal accross all occurrences, merge those arguments.
- Create a new function that will have the TwoNode as body. Generate placeholders for all children of the parent that are not the given child, and all children of the child. So here the function would be:
- Inline all functions that have just 1 caller. This is essential, because the above algorithm generates a ton of mini-functions whose body contains just one node, so this inlining is responsible for making those back into the largest possible functions, and shifting the boundaries of abstractions. Going down to one caller is a natural consequence of the above algorithm whenever a function call with multiple occurrences becomes the given child of a new function. Together, these parts of the algorithm create the “emergent” behavior of finding optimal function boundaries regardless of the code structure.
- To fully refactor code that has been edited by the user, it also needs to remove unused arguments which would otherwise block refactorings. This is not fully implemented yet.
The implementation
The most complete, most recent prototype shown above is written in C# with a gui in WPF. Some parts are incomplete, but there should be enough to experiment with if you’re interested in how it works.
You can get it from https://github.com/aardappel/restructor
You’ll want to load it up in Visual Studio, since the code it loads up initially is defined in Main.cs:TestCase(). You can uncomment different ones to try, or add new ones. You can also edit visually in the actual editor of course.
Since it uses WPF, it won’t run on Mono (Linux/OS X), sorry.
The actual algorithm starts of in Program.cs:Restructor(), see above for an outline of what it does. The same comments to the algorithm are in the code.
The language
The language was designed to be suitable for the algorithm as much as possible. To be a realistic test case, it has side effects, but otherwise it tries to be as (eagerly) functional as possible, since that makes refactors the easiest to follow.
It is statically typed with genericity for functions like map, reduce etc. So far it only has integers, floats, strings and lists, no way to define objects yet.
It has a lightweight way to define function values similar to C#, e.g. x => x * x, with () used for more than one parameter. It is using that same syntax to introduce variables in a scope, e.g. x = 2 => x * x equals 4.
History
An older prototype was in C++ with wxWidgets. A screenshot of what that looked like. If you actually want to run it, it is here, run RS/restructor.exe, or attempt to build the included source code.
For some reason it became messy pretty quickly, and the experience with it had gotten me an idea on how to simplify the implementation in a language with garbage collection (I’m generally not a fan of GC, but when doing complex graph manipulation it really helps). The better GUI library and tools for on-the-fly code generation were icing on the cake that led me to C# for the most recent prototype above.
It took me several years to get to a prototype at all. For some reason, the algorithm which is now pretty obvious took me a long time to figure out, in particular how to deal with sharing of values and side effects. Here are archeological artifacts of those days: a paper where I tried to explain what I was doing, some mockups for what the visual language could be structured like, and, if you really want to see what it looks like when someone’s mind goes around in circles, some brainstorm docs.
Related
A much simpler tool I wrote that works on any language: Sloppy. Leaves the refactoring to the human though :)